

In the first post of this series, we went through the ETL process used to transform a collection of papers/articles about Covid-19 and other infectious diseases into a SQLite database. In the second post, we saw how to generate weighted embedding vectors for important sentences in the corpus which can be used to quickly identify sentences and associated documents relevant to a user query. In this third and final post, I’ll show you how to use a BERT model fine-tuned on the SQuAD dataset to identify excerpts that are relevant to the user query from the body text of the top matching documents returned by the sentence embeddings search. The application source code is here.
I will not be going through the details of how BERT works. For that, I refer you to the following references:
- BERT original paper
- Tutorial about the attention mechanism that lies at the heart of BERT models
- Implementation of BERT and its variants
- Tokenization schemes: Byte pair encoding, word piece and sentence piece tokenization
Below, I’ll go through some of my implementation specific quirks. The flowchart the diagram below shows the workflow of applying BERT models to the full text of the documents returned by the sentence embedding search to retrieve answer spans.
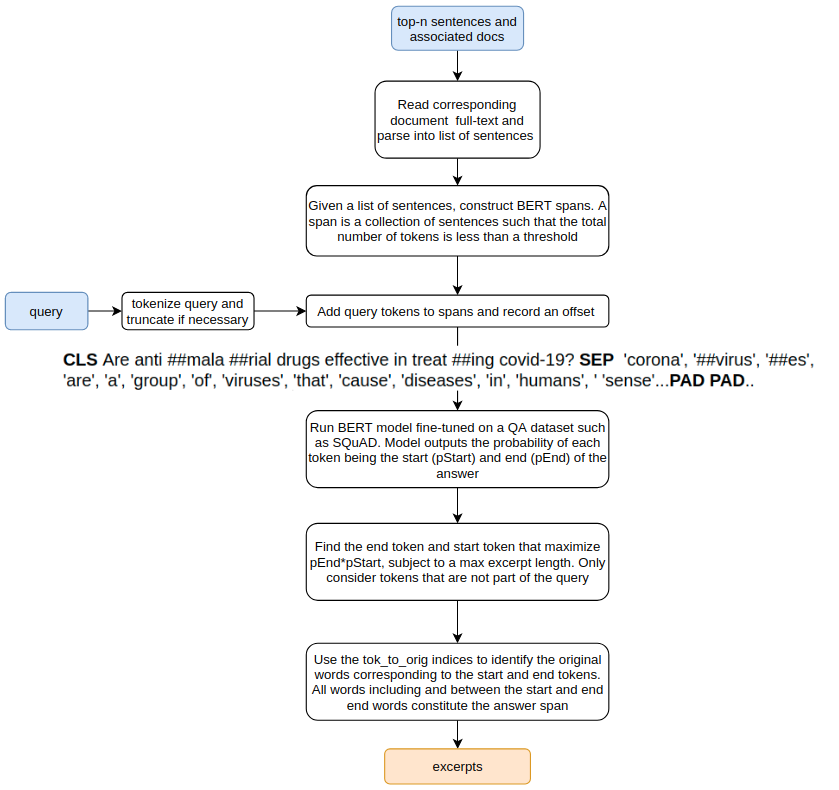
The diagram below shows this workflow being applied to the query “are antimalarial drugs effective in treating covid-19?”.
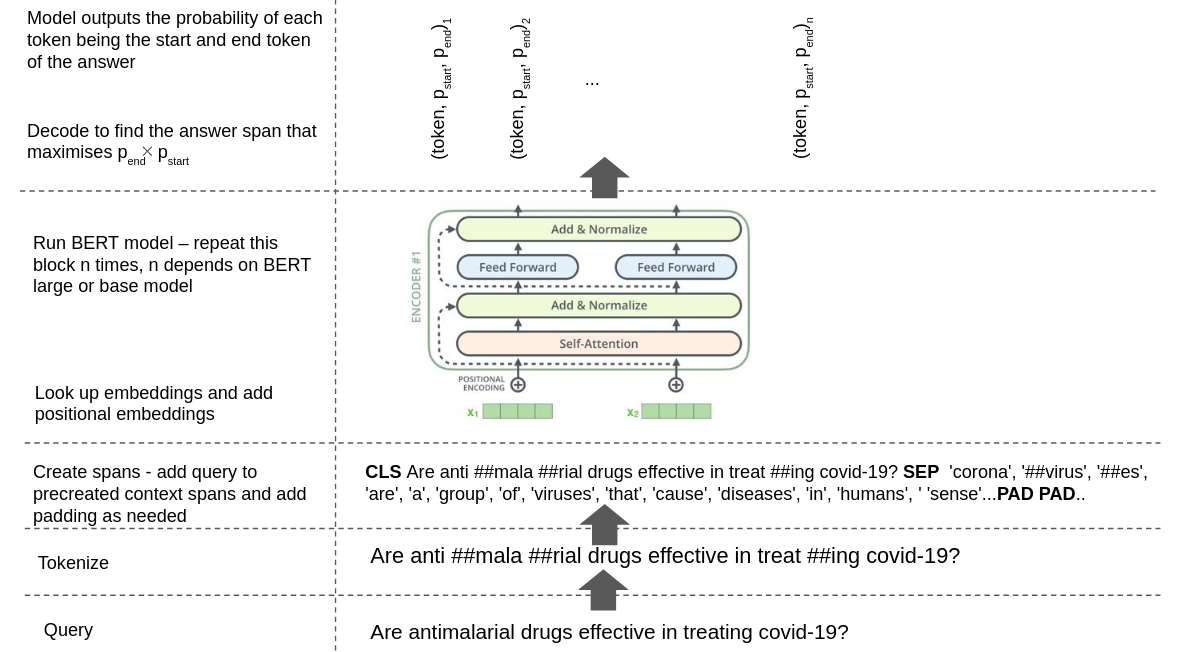
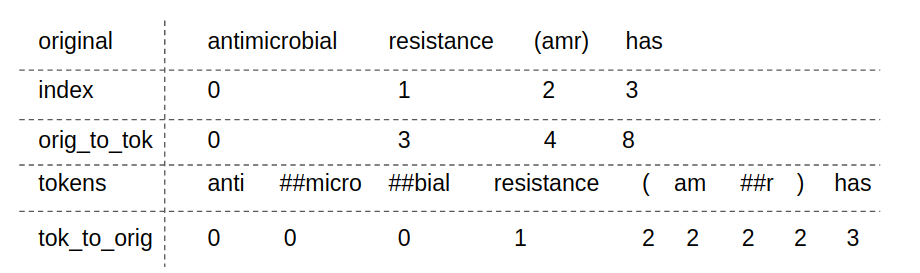
Let’s go through a few BERT implementation details that took me some time to understand. The first is the idea of maintaining mapping between token and word indices and vice versa. This is needed because BERT operates at the level of tokens rather than words. BERT uses the wordpiece tokenization scheme which splits up an input word into smaller units until the units are found in the vocabulary. BERT outputs the probabilities of each input token being the start or end of the answer span. These probabilities are input to a decoding module which produces token indices that maximize the product of the start and end probabilities subject to a maximum answer length constraint. These indices are at the token level rather than word level, and word spans are what users care about. To retrieve the original word indices, we maintain maps of token to original word indices, as shown in the picture below.
Spans is another important concept to understand. The input to a BERT model fine-tuned in a QA setting is a batch of query-context items. Each item in the batch is a concatenation of query tokens and context tokens separated by a special character (see diagram above). A context is simply a collection of sentences from the documents over which we wish to identify excerpts. Sentences are split into tokens and added to a context until the total number of tokens exceeds a threshold. When this occurs, we finalize that span and start processing a new one. Because we may exceed the max number of token threshold when we are midway through a sentence, we start with the beginning of the current sentence when we initiate a new span. This can result in portion of a sentence being part of one span and the complete sentence part of the next one, but does no harm other than increasing the number of spans (and thus the processing time) by a small amount. In my implementation (see preprocess function in src/covid_browser/fast_qa), I create these spans ahead of time, assuming a maximum query length. The flowchart below shows this process:
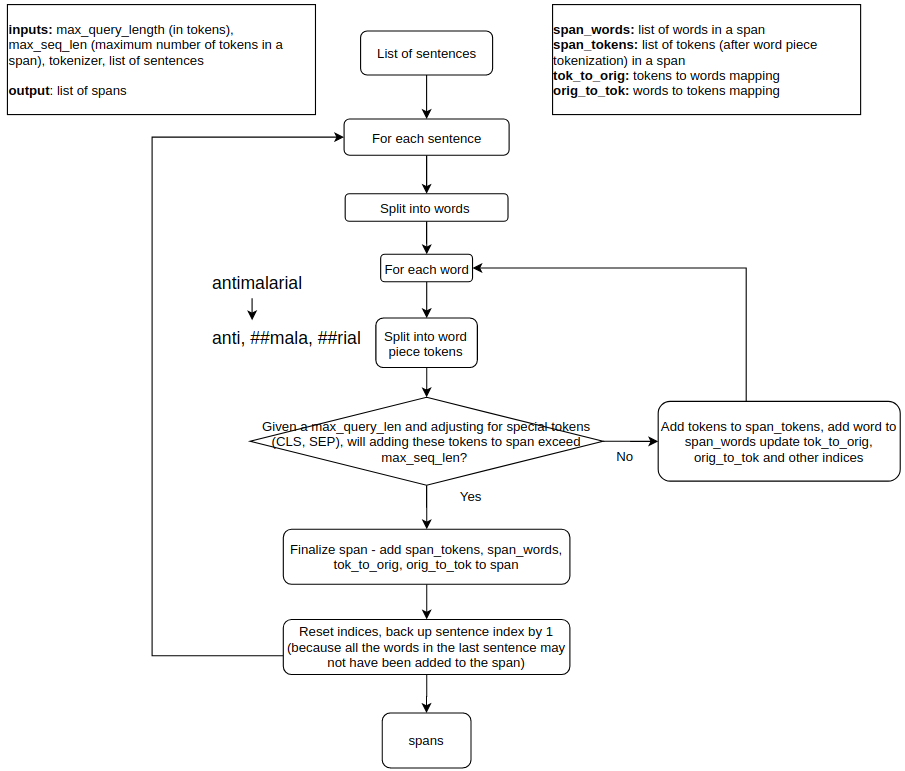
At query time, I add the tokenized query to each span and maintain an offset equal to the query length, which is later used to adjust the token to word indices.
This may not make much sense if you are not familiar with how BERT preprocessing works. I recommend running the code in a debugger and stepping through the preprocessing steps to get a feel for what’s going on.
A few pitfalls to be aware of:
- If you are using an English vocabulary but processing a document in another language (eg. spanish), then tokenization can take a long time because the wordpiece tokenizer must continue splitting up words into smaller tokens before the tokens are found in the vocabulary due to the language mismatch. I hack around this issue by rejecting documents that contain non-ascii characters such as characters with accent marks, which don’t occur in English. I also terminate span creation if the total time exceeds a threshold (2 seconds).
- Some sentences (such as those containing long mathematical formulas) can exceed the total number of tokens threshold after tokenization. Such sentences must be appropriately truncated.
Data Parallel Forward Pass
I have two 1080Ti GPUs on my deep learning machine. To speed up forward pass through the BERT model, I split up the batch along the batch dimension and use Python’s futures library to execute the forward pass in parallel. Here’s the code (see parallel_execute2 in fast_qa)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
def fwd_pass(params): # This will be called in parallel for each GPU model, input_ids, attention_mask, token_type_ids = params print(model.device) # using no_grad is very important - this way Pytorch doesn't allocate space for gradients, reducing the # chances of getting Cuda OOM errors with torch.no_grad(): # send the input arguments to the correct GPU. fw_args = {"input_ids": input_ids.to(model.device), "attention_mask": attention_mask.to(model.device), "token_type_ids": token_type_ids.to(model.device)} start, end = model(**fw_args) start = start.cpu() end = end.cpu() return start, end def parallel_execute2(models, fw_args): # num_chunks corresponds to the number of GPUs. We already sent a model replica to each GPU num_chunks = len(models) start = torch.FloatTensor() end = torch.FloatTensor() input_ids = fw_args.get('input_ids') attention_mask = fw_args.get('attention_mask') token_type_ids = fw_args.get('token_type_ids') # split along batch dimension input_ids_ = torch.chunk(input_ids, num_chunks, dim=0) attention_mask_ = torch.chunk(attention_mask, num_chunks, dim=0) token_type_ids_ = torch.chunk(token_type_ids, num_chunks, dim=0) futures = [] with concurrent.futures.ThreadPoolExecutor() as executor: for model, token_ids, attention_mask, token_type_ids in zip(models, input_ids_, attention_mask_, token_type_ids_): futures.append(executor.submit(fwd_pass, (model, token_ids, attention_mask, token_type_ids))) # collect results for future in futures: start_, end_ = future.result() start = torch.cat((start, start_.cpu()), 0) end = torch.cat((end, end_.cpu()), 0) return start, end |
The total query processing time is ~3 seconds split into three major components – BERT execution time (~1.8 sec), span creation time (~1 sec) and top-n embedding look time (0.1 sec)
This concludes this series of posts. I think this Covid-19 information retrieval system is a great example of combining conventional natural processing techniques such as TF-IDF and word embeddings with modern neural network based techniques such as BERT. I hope you found these posts useful, please leave a comment if you did.
Leave a Reply