

The purpose of this post is to provide math proofs and clarify some implementation details in the recently introduced reinforcement learning method called “Trust Region Policy Optimization” (TRPO). Standard policy gradient methods try to find a policy that maximize expected rewards by solving the optimization problem:
(1) ![\begin{equation*} \begin{align} \max_\theta J(\pi_\theta) = E_{\tau \sim \pi_\theta}[\sum_{t=0}^\infty \lambda^t r_t ] \end{align} \end{equation*}](https://telesens.co/wp-content/ql-cache/quicklatex.com-f4bc5bfcba9acffb6f67bfee58766669_l3.png "Rendered by QuickLaTeX.com")
This problem is solved by performing stochastic gradient ascent on the policy parameters. For more details, refer to the excellent lecture slides on “Advanced Policy Gradient Methods” as part of the Reinforcement Learning class at UC Berkeley. As a side note, I applaud the recent trend in academia to make class lecture notes at top universities available to everyone. This, accompanied by a similar trend in research to make code for new machine learning algorithms available is making it possible for anyone willing to put in the time and effort to master latest advances in machine learning. This spirit of openness will make the field accessible to talented minds all over the world who may lack the means to go to Stanford or Berkeley and help address the growing mismatch between the supply of and demand for machine learning practitioners.
The problem is that this approach offers no principled way to choose the right step size. If the step size is too big, the optimization may miss the minimum. If the step is too small, progress may be very slow. Standard machine learning methods address this problem by using automatic learning rate adjustment such as the Adam optimizer. However as illustrated in the lecture slides, the problem with the policy gradient methods is that small changes to the policy network parameters can cause unexpectedly large changes in the policy output (action probabilities).
TRPO offers a mathematically principled approach to this problem by re-framing the optimization problem as a constrained optimization whose solution is guaranteed to result in an improved policy. For details, refer to the lecture slides and the original TRPO paper. There are many PyTorch implementations of TRPO available. I’m using this one – https://github.com/Khrylx/PyTorch-RL. PyTorch is my favorite machine learning library. Someone I know recently said – “Looking at TensorFlow code gives me a headache, using PyTorch makes me smile”. I agree with that sentiment :-).
Parts of this code took me considerable effort to understand, particularly the proof of the fast method to calculate the Fisher vector product and its PyTorch implementation. The main purpose of this post is to offer explanations for the math and code so that it will be easier for you to follow. I’ll focus on the TRPO step and assume you already understand how to calculate value functions, compute advantages and other standard reinforcement learning techniques that are not specific to TRPO.
The constrained optimization problem solved in TRPO is stated as follows:
(2) 

Here  is defined as
is defined as
(3) 
 refers to the output of the network (at the
refers to the output of the network (at the  iteration) with parameters
iteration) with parameters  , representing a probability distribution over the action space.
, representing a probability distribution over the action space.  is short for
is short for  , the subscript may be dropped in some places below as the dependence of the policy on the network parameters is implicit. Since and hence is fixed (at the end of iteration
, the subscript may be dropped in some places below as the dependence of the policy on the network parameters is implicit. Since and hence is fixed (at the end of iteration  ), the only variable in the formula above is . Therefore, while calculating derivatives using autograd, we must detach from the computation graph. The summation is over the elements of the
), the only variable in the formula above is . Therefore, while calculating derivatives using autograd, we must detach from the computation graph. The summation is over the elements of the  dimensional vector, the output of the policy network.
dimensional vector, the output of the policy network.
|
1 2 3 4 5 6 7 |
def get_kl(self, x): action_prob1 = self.forward(x) # calling .data detaches action_prob0 from the graph, so it will not be part of the gradient computation. # Also, starting PyTorch 0.4, the Variable wrapper is no longer needed. action_prob0 = Variable(action_prob1.data) kl = action_prob0 * (torch.log(action_prob0) - torch.log(action_prob1)) return kl.sum(1, keepdim=True) |
The loss function is defined as
(4) ![\begin{equation*} \begin{align} L(\pi) = E_{\tau \sim \pi_k}[\sum_{t=0}^\infty \gamma^t \frac{\pi(a_t|s_t)}{\pi_k(a_t|s_t)}A^\pi(s_t, a_t)] \end{align} \end{equation*}](https://telesens.co/wp-content/ql-cache/quicklatex.com-276961d07a2f44144288e43a4beccb09_l3.png "Rendered by QuickLaTeX.com")
The gradient of this loss function wrt to the policy parameters  is:
is:
(5) ![\begin{equation*} \begin{align} \nabla_\theta L(\pi)|\theta = \theta_k = E_{\tau \sim \pi_k}[\sum_{t=0}^\infty \gamma^t \nabla_\theta \log\pi_\theta(a_t|s_t)|_{\theta = \theta_k} A^{\pi_{\theta_k}}(s_t, a_t)] \end{align} \end{equation*}](https://telesens.co/wp-content/ql-cache/quicklatex.com-7d87ef75be9da409b9cee7eb56b29e19_l3.png "Rendered by QuickLaTeX.com")
This gradient can be readily computed as the state-action sequence under the current policy is already available. The code to calculate the loss and gradient is shown below. We compute the policy gradient both using autograd and the formula above.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
###### # Run forward pass on a state to get the probability distribution over actions action_prob = policy_net.forward(states[0]) # Let's look at the first action log_prob = torch.log(action_prob[actions[0]]) # detach from the graph so we don't compute derivative wrt this fixed_log_prob = log_prob.detach() # Formula for loss. Need to exponentiate the log prob to get prob. # Advantages have been computed earlier in the program action_loss = Variable(advantages[0]) * torch.exp(log_prob - fixed_log_prob) # Compute derivative using autograd grad1 = torch.autograd.grad(action_loss, policy_net.parameters(), retain_graph=True) # grad_flat will be a vector K*1, where K is the total number of parameters # in the policy net. grad1_flat = torch._utils._flatten_dense_tensors(grad1) # Now compute derivative using policy gradient formula _grad2= torch.autograd.grad(log_prob, policy_net.parameters()) _grad2_flat = torch._utils._flatten_dense_tensors(_grad2) grad2 = advantages[0]*grad2_flat # verify grad2 == grad1 ####### |
Here  is the state action sequence generated by following , the policy at time step . The goal is to find the optimal new policy that is guaranteed to decrease the loss function
is the state action sequence generated by following , the policy at time step . The goal is to find the optimal new policy that is guaranteed to decrease the loss function
Expanding the loss function and the KL distance using Taylor series expansion around ,
(6) 
(7) 
Here  and
and  . The first two terms in the expansion for KL distance vanish – the first term because the KL distance between two identical distributions is 0 and the second term because the KL distance achieves a minimum at
. The first two terms in the expansion for KL distance vanish – the first term because the KL distance between two identical distributions is 0 and the second term because the KL distance achieves a minimum at  (since KL distance is a distance, it can’t be lower than 0). Thus the first derivative of
(since KL distance is a distance, it can’t be lower than 0). Thus the first derivative of  at must be 0.
at must be 0.
Thus, our optimization problem reduces to:
(8) 
To avoid getting lost in a sea of symbols, lets look at the dimensions of the vectors in the expression above.  is the gradient of the loss wrt the policy network parameters, and hence must have dimension equal to the number of parameters. Thus is a
is the gradient of the loss wrt the policy network parameters, and hence must have dimension equal to the number of parameters. Thus is a  vector. being the parameter vector is also . Thus,
vector. being the parameter vector is also . Thus,  is a scalar quantity. Similarly, the expression in the constraint has dimensions
is a scalar quantity. Similarly, the expression in the constraint has dimensions  .
.
As shown in appendix C of the TRPO paper, this problem is solved in two steps – first a search direction for is computed and then a maximum distance along this direction is calculated such that the constraint is still satisfied. The direction can be calculated by applying the Lagrange multiplier technique (this is my own proof, the appendix in the TRPO paper just shows the final result). Denoting  by
by  , the Lagrange multiplier by
, the Lagrange multiplier by  and the Lagrangian by
and the Lagrangian by  , the expression for the Lagrangian is given by
, the expression for the Lagrangian is given by
(9) 
Differentiating wrt and setting to 0,

Thus, the direction along which we must search for the new policy parameters is given by solving  . Now we must determine how far to move along this direction so that the constraint is satisfied. Let this distance be denoted by
. Now we must determine how far to move along this direction so that the constraint is satisfied. Let this distance be denoted by  . Thus,
. Thus,  . Substituting this in the expression for KL constraint, we get
. Substituting this in the expression for KL constraint, we get  , and thus
, and thus  . The product of and gives the optimal step to update . This mathematical principled method to compute the step size and direction is the major contribution of TRPO. Compare this with the ad hoc “learning rate schedule” typically used in training neural networks.
. The product of and gives the optimal step to update . This mathematical principled method to compute the step size and direction is the major contribution of TRPO. Compare this with the ad hoc “learning rate schedule” typically used in training neural networks.
In practice, since both the loss function and the KL divergence are non-linear functions of the parameter vector (and thus depart from the linear/quadratic approximations used to compute the step) a line search is performed to find the largest fraction of the maximum step size that leads to a decrease in the loss function.
Thus, to compute the optimal step, we must do the following:
- Step 1: Compute search direction by solving
- Step 2: The maximum step size is computed by using the formula
The matrix  is a
is a  matrix where K is the total number of parameters in the policy net and easily be in the 10’s of thousands. To store this matrix and compute its inverse is very expensive. Note however that we are interested in the matrix-vector product
matrix where K is the total number of parameters in the policy net and easily be in the 10’s of thousands. To store this matrix and compute its inverse is very expensive. Note however that we are interested in the matrix-vector product  , not the matrix
, not the matrix  by itself. This product can be calculated using conjugate gradient techniques which require repeated calculations of
by itself. This product can be calculated using conjugate gradient techniques which require repeated calculations of  .
.  is a vector that changes every conjugate gradient iteration. This simplifies matters, however calculating the Hessian matrix itself is a problem for autograd because its automatic differentiation feature is designed to calculate the derivative of a scalar wrt a vector, whereas the Hessian matrix involves the derivative of a vector (the derivative of the loss wrt the policy parameters) wrt a vector (policy parameters). One could of course loop over each element of the vector (code shown below), however this would be very slow, and require a lot of storage to store a Hessian matrix where
is a vector that changes every conjugate gradient iteration. This simplifies matters, however calculating the Hessian matrix itself is a problem for autograd because its automatic differentiation feature is designed to calculate the derivative of a scalar wrt a vector, whereas the Hessian matrix involves the derivative of a vector (the derivative of the loss wrt the policy parameters) wrt a vector (policy parameters). One could of course loop over each element of the vector (code shown below), however this would be very slow, and require a lot of storage to store a Hessian matrix where  is a large number (in the thousands).
is a large number (in the thousands).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def hessian(network, states): #pa = network.forward(states) pa_sum = network.get_kl(states) # calculate the first derivative of the loss wrt network parameters J = torch.autograd.grad(pa_sum, network.parameters(), create_graph=True, retain_graph=True) J_ = Tensor().cuda() # concatenate the various gradient tensors (for each layer) into one vector for grad in J: J_ = torch.cat((J_, grad.view(-1)), 0) H = Tensor().cuda() # calculate gradient wrt each element and concatenate into the Hessian matrix for Ji in J_: JJ = torch.autograd.grad(Ji, network.parameters(), create_graph=False, retain_graph=True) JJ_ = torch.cat([grad.contiguous().view(-1) for grad in JJ]) H = torch.cat((H, JJ_), 0) # numParams is the number of parameters in the network numParams = sum(p.numel() for p in network.parameters() if p.requires_grad) HH = H.view((numParams, numParams)) return HH |
Using a nice math trick, we can avoid calculating the full Hessian matrix to calculate the matrix-vector product. Here’s how this works. The  element of is given by:
element of is given by:

The element of  , the matrix vector product is:
, the matrix vector product is:
(10) 
The full vector  . Thus, the matrix vector product can be calculated by first calculating the first derivative of the KL distance wrt the network parameters and the product of this derivative vector with the input vector. This gives a scalar. We then calculate the derivative of this scalar quantity wrt the parameter vector which gives the desired matrix-vector product. This is called the “direct method” and the code is shown below:
. Thus, the matrix vector product can be calculated by first calculating the first derivative of the KL distance wrt the network parameters and the product of this derivative vector with the input vector. This gives a scalar. We then calculate the derivative of this scalar quantity wrt the parameter vector which gives the desired matrix-vector product. This is called the “direct method” and the code is shown below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def Fvp_direct(network, states, v): damping = 1e-2 #pa = network.forward(states) pa_sum = network.get_kl(states) # compute the first derivative of the loss wrt the network parameters and flatten into a vector grads = torch.autograd.grad(pa_sum, network.parameters(), create_graph=True) grads_flat = torch.cat([grad.view(-1) for grad in grads]) # compute the dot product with the input vector grads_v = torch.sum(grads_flat * v) # now compute the derivative again. grads_grads_v = torch.autograd.grad(grads_v, network.parameters(), create_graph=False) flat_grad_grad_v = torch.cat([grad.contiguous().view(-1) for grad in grads_grads_v]).data return flat_grad_grad_v + v * damping |
Is this the best we can do? Turns out that by doing some math in advance, we can save some computation time.
(11) 
From now on, we’ll refer  by
by  or just
or just  . Recall that the KL distance is a function of the action probability distribution output by the policy net whose parameters are specified by .
. Recall that the KL distance is a function of the action probability distribution output by the policy net whose parameters are specified by .  represents the network output at iteration and is a fixed quantity.
represents the network output at iteration and is a fixed quantity.
We are interested in the analytical expression for the Hessian matrix of evaluated at i.e., 
Taking the first derivative wrt and applying the chain rule,
(12) 
Here  is a
is a  vector and
vector and  is a
is a  vector. Thus
vector. Thus  is a
is a  vector, as we would expect
vector, as we would expect  to be.
to be.
Differentiating again wrt and applying the product rule for derivatives,
(13) ![\begin{equation*} \begin{align} \frac{\partial}{\partial\theta}\frac{\partial{\pi}}{\partial{\theta}} \frac{\partial{D_{KL}(\pi)}}{\partial{\pi}} = \frac{\partial^2{\pi}}{\partial{\theta^2}} \frac{\partial{D_{KL}(\pi)}}{\partial{\pi}} + \frac{\partial{\pi}}{\partial{\theta}}[\frac{\partial}{\partial{\theta}} \frac{\partial{D_{KL}(\pi)}}{\partial{\pi}}] \end{align} \end{equation*}](https://telesens.co/wp-content/ql-cache/quicklatex.com-a009ead177c8fe6fc24617f6bf364919_l3.png "Rendered by QuickLaTeX.com")
The first term vanishes at (refer to the Taylor series expansion of the KL distance above for an explanation). You may wonder why did not vanish in equation 12 above. This is because we are not evaluating the expression at until we take the second derivative. This is the same reason why the second derivative of  at
at  is 2 while the first derivative at is 0.
is 2 while the first derivative at is 0.
Considering the second term in the equation above,
(14) ![\begin{equation*} \begin{align} \frac{\partial{\pi}}{\partial{\theta}}[\frac{\partial}{\partial{\theta}} \frac{\partial{D_{KL}(\pi)}}{\partial{\pi}}] = \left( \frac{\partial{\pi}}{\partial{\theta}} \right) \frac{\partial^2{D_{KL}(\pi)}}{\partial{\pi^2}} \left( {\frac{\partial{\pi}}{\partial{\theta}}} \right) ^T \end{align} \end{equation*}](https://telesens.co/wp-content/ql-cache/quicklatex.com-093ea3ded565cddaae4898c4db70c8f8_l3.png "Rendered by QuickLaTeX.com")
The transpose ensures that the dimensions of the product matches up. is  ,
,  is
is  and thus the product above has dimensions
and thus the product above has dimensions 
Now let’s look at the middle term in this expression which can be evaluated analytically.
(15) 
Taking the first derivative and keeping in mind that  is a constant,
is a constant,
(16) 
Here  is a vector. Now taking the second derivative and noting that
is a vector. Now taking the second derivative and noting that  where
where  is the
is the  component of the vector,
component of the vector,
![\begin{equation} \begin{align} \frac{\partial^2}{\partial{\pi^2}}D_{KL}(\pi)&= \[ \begin{bmatrix} \frac{\pi(\theta_k)_1}{\pi(\theta)_1^2} & 0 & \dots \\ \vdots & \ddots & \\ 0 & & \frac{\pi(\theta_k)_M}{\pi(\theta)_M^2} \end{bmatrix} \] \end{align} \end{equation}](https://telesens.co/wp-content/ql-cache/quicklatex.com-e7d845c9a20f28548c31d4b65cc73195_l3.png "Rendered by QuickLaTeX.com")
Here,  denotes the component of the vector.
denotes the component of the vector.
Evaluating the expression above at , we get
![\begin{equation} \begin{align} \frac{\partial^2}{\partial{\pi^2}}D_{KL}(\pi)|_{\theta = \theta_k} &= \[ \begin{bmatrix} \frac{1}{\pi(\theta_k)_1} & 0 & \dots \\ \vdots & \ddots & \\ 0 & & \frac{1}{\pi(\theta_k)_M} \end{bmatrix} \] \end{align} \end{equation}](https://telesens.co/wp-content/ql-cache/quicklatex.com-7662b20cda6e496432e98fc1d3c12f06_l3.png "Rendered by QuickLaTeX.com")
Since non-diagonal terms of this matrix are zero, it can be compactly expressed as a vector, consisting of the non-zero diagonal elements. This explains the following code used in the computation of the KL divergence Hessian:
|
1 2 3 4 5 6 |
def get_fim(self, x): action_prob = self.forward(x) # M represents the second derivative of the KL distance # against the action probabilities M = action_prob.pow(-1).view(-1).data return M, action_prob, {} |
The process of calculating the full product
(17) 
is shown in the slides below:




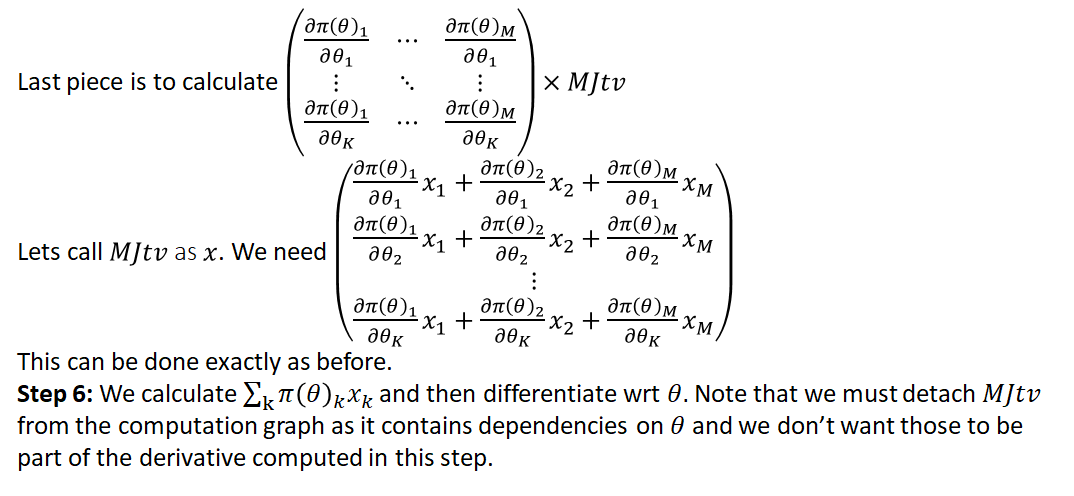
And the code with the steps marked is shown below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
def Fvp_fim(network, states, v): damping = 1e-2 t_beg = time.process_time() M, mu, info = network.get_fim(Variable(states)) mu = mu.view(-1) # M is the second derivative of the KL distance wrt network output (M*M diagonal matrix compressed into a M*1 vector) # mu is the network output (M*1 vector) t = Variable(ones(mu.size()), requires_grad=True) # Step 1 mu_t = (mu * t).sum() # Step 2 Jt = compute_flat_grad(mu_t, network.parameters(), filter_input_ids=set(), create_graph=True) # Step 3 Jtv = (Jt * Variable(v)).sum() # Step 4 Jv = torch.autograd.grad(Jtv, t, retain_graph=True)[0] # Step 5 MJv = Variable(M * Jv.data) # Step 6 mu_MJv = (MJv * mu).sum() JTMJv = compute_flat_grad(mu_MJv, network.parameters(), filter_input_ids=set(), retain_graph=True).data # JTMJv /= states.shape[0] elapsed_time = time.process_time() - t_beg global fim_t fim_t += elapsed_time return JTMJv + v * damping |
This method turns out to be about 20% faster than the direct method. This is largely because we are calculating the derivatives of the actions with respect to the network parameters instead of with respect to the KL distance, which is a complex function of the actions. This is a good example of how doing some math in advance yields decent speed-ups over relying on software to do all the derivative calculation.
That’s it! Hope this post will help you with understanding the implementation of TRPO. I welcome your comments/feedback.
i have a question about solving the differentiating wrt s of equation (9) and setting to 0, why the search direction is given by Hs=g? where is lambda? Is g = 1/(lambda)*g?
thank you a lot!
Lambda is a scalar, so it doesn’t affect the search direction vector. The size of the search vector is computed in the next step. Makes sense?
yes, I understand that. Thanks for your reply!
I have a question. Why we need
v * dampingthis part in lastreturn JTMJv + v * damping?I think just JTMJv is answer.
I have one question. why we need damping? I think just
JTMJvis ok. why we returnJTMJv + v * dampinglike this?That is just a damping technique used in conjugate gradient methods to make it more stable. See page 3 of this reference: http://www2.maths.lth.se/vision/publdb/reports/pdf/byrod-eccv-10.pdf
After Eq. 9, why “Differentiating wrt s” won’t lead to “∂(H)/∂(s)”? H and s are both related to θ.
yes, but we are differentiating wrt s, not theta. Derivative of g(x)f(x) wrt g(x) = f(x)