

So you developed a cool AI algorithm and want to show it off through a web service? You know a lot about AI algorithms and Python, but not as much about web technologies? If you answered yes to any of these questions, the information in this post should be helpful. These are lessons learnt from putting together the “AttentionGAN” web service. I’m no expert in web technologies, so for the most part, I’ll simply describe what I did and provide helpful links rather than make recommendations. Hopefully, others working on a similar task will find this information helpful.
System Information
The Attention GAN demo runs on an Amazon Lightsail Ubuntu instance with the LAMP stack (Linux operating system, the Apache HTTP Server, the MySQL relational database management system, and the PHP programming language) installed. I migrated my website to Amazon Lightsail few months ago and very happy so far. I particularly like the snapshot feature that enables painfree upgrade to a more powerful host. One feature that is particularly important for hosting deep learning applications that is lacking on Lightsail – hosts with GPUs. Hopefully these will be available soon.
For setting up my web service I needed to install Python (3.6), change various Apache and Bitnami configuration files and set the right permissions. In the next few sections, I’ll describe what was non-obvious to me about each of these steps.
Python Installation
My default Bitnami installation came with Python 2.7. Since my Python code was based on Python 3.6, I needed to install Python 3.6. Instructions for installing core Python 3.6 are provided in this post and also repeated below for convenience
|
1 2 3 |
sudo add-apt-repository ppa:deadsnakes/ppa sudo apt-get update sudo apt-get install python3.6 |
By default, the Python executable (called python3.6) will be installed in /usr/bin. I set up an alias to this file by adding the following to my ~/.bash_aliases file
|
1 |
alias python3=/usr/bin/python3.6 |
so now when I type python3, it automatically points to the correct executable. “python” still points to the existing Python 2.7 installation, which was needed by some other programs on my system.
The modules installed with this core Python installation are located in /usr/lib/python3.6
The steps listed above will install the binary version of Python 3.6. I also need the development version that includes C/C++ headers (such as python.h) to compile mod_wsgi (described later). The development version can be installed using the following command.
|
1 |
sudo apt-get install python-dev |
The headers will be installed at /usr/include/python3.6m/
Notice that the packages above are installed in core Linux directories (/usr), and therefore need sudo.
Next, I installed Pytorch. As mentioned in Pytorch install instructions, Pytorch can be installed using:
|
1 |
pip3 install torch torchvision --user |
Note the “–user”. With this option, Pytorch will be installed in the home directory (/home/bitnami/.local/lib/python3.6/site-packages in my case). Since the core Linux directories are not modified, we can run this command without sudo.
Other packages such as Flask and gunicorn can be installed in a similar manner.
Linux Permissions
Next, a few words about Linux permissions. Linux has an elaborate system for managing file ownership and permissions. There are two concepts – ownership and permissions. A file (or directory) has an owner and belongs to a group. Those are managed by “chown” and “chgrp” commands. The owner and the group have varying degrees of access (read/write/execute) to the file. Those are managed by the chmod command. I will not go into this topic in further detail as there are many articles on the web (this for example) that do a good job at explaining how to manage ownership and permissions. Understanding these concepts is quite important as incorrect ownership and permissions settings can cause things to not work in mysterious ways. For instance, if you want your web server (Apache in my case) to have access to a directory, that directory (and the files and directory contained in it) must allow the user or group the web server runs as to be able to access the directory. We’ll see an example later.
Apache Configuration Parameters
Lastly, to provide Apache access to the client/server files and expose my web service to the internet, I need to modify the Apache configuration files. It is helpful to understand where these files are located and how they are referenced.
In a standard Bitnami distribution, the root Apache config file is located in /opt/bitnami/apache2/conf/bitnami/httpd.conf. This file contains settings such as which port Apache listens on (open the file in a text editor and search for “Listen”), which user/group Apache runs as (search for “Group”), which modules Apache loads on startup (search for LoadModule statements), where Apache access/error logs are located (search for “access_log” and “error_log”) are located etc.
At the bottom of this file, the Bitnami specific configuration files are included:
|
1 2 |
Include "/opt/bitnami/apache2/conf/bitnami/bitnami.conf" Include "/opt/bitnami/apache2/conf/bitnami/httpd.conf" |
The bitnami.conf file in turn includes the bitnami-apps-prefix.config. The user can insert their application specific configuration files in this file.
Exposing a Python Application as a web service
My application program runs inference on the AttnGan network. The program performs two tasks. The first task is “init” which initializes the AttnGan network by loading the network weights from the disk and setting up the network architecture. Second task is “generate” which runs a user provided caption through a word encoder and then through the AttnGan network. To make the system accessible through a web service, a user must be able to call these methods over the internet and pass parameters (for example, caption string to the generate function).
This can be achieved using the Flask framework. With Flask, you “decorate” your Python functions that you want to be accessible through a web service with @app.route decorators. For example, with the decoration shown below, the generate function will be called with caption and modelname as the arguments when the user issues a HTTP request website-base-url/generate/caption/modelname. Here caption and modelname can be user provided strings.
|
1 2 |
@app.route('/generate/<caption>/<modelname>', methods=['POST']) def generate(caption, modelname): |
Flask’s documentation is very good and there are lots of tutorials available on the web for learning about Flask. Before proceeding further, you should get the Flask minimal application working and then add the Flask decorators to the relevant functions in your Python code and make sure you are able to call those functions from a web client.
Exposing your Client Application to the web server (Apache)
Once your Flask based web service is working locally, the next step is to make it available to Apache, which will in turn make it internet accessible. My application set up looks like this:
my-app-path/AttnGAN:
client: contains the files that implement client front end (html, css, javascript)
server: contains the python files, Attention model data, model configuration files etc.
conf: web service configuration files
First step is to set up the alias for the client part of your application (the HTML/JS/CSS files that form your application frontend) and give Apache permissions to access your client files. This can be done by creating a httpd-app.conf (or whatever you want to call it) file with the following content:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Alias /attngan "/your-app-path/AttnGAN/client" <Directory /your-app-path/AttnGAN/> Options +FollowSymLinks AllowOverride None <IfVersion < 2.3 > Order allow,deny Allow from all </IfVersion> <IfVersion >= 2.3> Require all granted </IfVersion> </Directory> |
This tells Apache the mapping between a URI (/attngan in the example above) and the application directories, and it gives Apache permissions to access those directories. Now when the user goes to website-base-url/attngan/caption.html, Apache is able to serve caption.html from the /your-app-path/AttnGan/client directory. To tell Apache about httpd-app.conf, I added a include directive for this file in my bitnami-apps-prefix. conf
|
1 |
Include "path-to-your httpd-app.conf" |
This is all pretty standard web configuration stuff.
Next up is setting up your server so that your client can access it via Apache. I experimented with two ways to do this, and I’ll describe each in some detail in the following sections.
Apache + mod_wsgi
The mod_wsgi package implements a simple to use Apache module which can host any Python web application which supports the Python WSGI specification. It essentially enables Apache to launch your Python server as daemon processes and route HTTP requests to these processes using the WSGI interface. As the mod_wsgi documentation says, there are two ways to set up mod_wsgi:
- As a traditional Apache module installed into an existing Apache installation
- Installing mod_wsgi into your Python installation or virtual environment
I only tried option #1.
Building and Installing mod_wsgi
To avoid compatibility issues, I decided to build mod_wsgi from source. This is fairly easy to do. Follow directions here. On a Bitnami installation, the location of the Apache apxs file will be different, so your configure command will look like:
|
1 |
./configure --with-apxs=/opt/bitnami/apache2/bin/apxs --with-python=/usr/bin/python3.6 |
after configuring your environment, run make. Then copy the generated mod_wsgi.so from <location-of-mod_wsgi>/src/server/.libs/ to opt/bitnami/apache2/modules/
The last step is to ask Apache to load mod_wsgi. This is done by adding
|
1 |
LoadModule wsgi_module modules/mod_wsgi.so |
to your Apache httpd.conf file.
Now when you restart Apache, mod_wsgi should be loaded.
Configuring WSGI
Next step is to create a configuration for WSGI. This looks like the following on my set up (attngan-wsgi-config.conf):
|
1 2 3 4 5 |
WSGIDaemonProcess /your-app-path/AttnGAN/server/attnGANserver.py python-path='/home/bitnami/.local/lib/python3.6/site-packages/' user=bitnami group=daemon processes=1 threads=1 display-name=attnGANserver1 WSGIApplicationGroup %{GLOBAL} WSGIPythonHome /usr WSGIScriptAlias /attn_gan_impl /opt/bitnami/apps/AttnGAN/server/attn_gan.wsgi |
Let’s look at some of these options. There are two ways to run WSGI applications. First (the default) option is called “embedded mode”. In this mode the application will be hosted within the Apache worker processes used to handle normal static file requests. the second option is called “daemon mode”. In this mode, a set of processes is created for hosting a WSGI application, with any requests for that WSGI application automatically being routed to those processes for handling. This is better as if you make changes to your python code, those can automatically be picked up by Apache without having to restart the server. The WSGIDaemonProcess directive shown above sets up this mode. The first argument is the path to your python server file, second option (python-path) adds your site-packages folder to the WSGI python path. This is needed because many of the Python packages are installed in .local/lib which is not on the system python path. If you don’t do this, you may get many module not found errors. The options specify how many processes and threads to launch. I’ll come back to that later.
The WSGIPythonHome directive should point to your base Python installation. This should be the output of running
|
1 2 |
import sys print(sys.prefix) |
in a Python 3.6 shell.
The WSGIScriptAlias directive sets the mapping between the URI mount point of your Python server (/attn_gan_impl) and the absolute path name for the WSGI application file, which we’ll look at next.
There are restrictions on where these directives can live – for example the WSGIScriptAlias directive cannot be used within either of the Location, Directory or Files container directives, WSGIPythonPath cannot occur within <VirtualHost> section and so on. See WSGI configuration guide for details. This imposes restrictions on where this WSGI configuration file can be placed in the various Apache configuration files. In my setup, I placed the configuration file with the directives shown above directly at the bottom of my httpd.conf
|
1 |
Include "my-app-path/AttnGAN/conf/attgan-wsgi-config.conf" |
Note that there is no requirement that the WSGI directives be in one file. You are free to split them up as you wish. I put them all in one file to make it easier to keep track.
WSGI Application
Now for the content of the WSGI application file. The job of this file is to define the application object that will serve as the entry point of your Python application. A good place to start is the following wsgi (attn_gan.wsgi) file. This file obtains the Python version and prefix and returns that information after wrapping it into a HTTP header.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import sys import os def application(environ, start_response): status = '200 OK' output = u'' output += u'sys.version = %s\n' % repr(sys.version) output += u'sys.prefix = %s\n' % repr(sys.prefix) response_headers = [('Content-type', 'text/plain'), ('Content-Length', str(len(output)))] start_response(status, response_headers) return [output.encode('UTF-8')] |
Before you run this, you should make sure that Apache has the right permissions to access the folder where your server files are located. The easiest way to do this is to change the group of your server directory (and its contents) to the group Apache runs as (daemon in my case) using chgrp and then make sure the group has the right permissions. For setting the permissions, I simply copied the permissions from another folder that Apache had access to my server folder. This can be done using the chmod –reference option
|
1 |
chmod --reference=RFile file |
To make the above recursive, run it with the -R option.
When you run this in a browser (http://127.0.0.1/attn_gan_impl), you should get something like this:
|
1 2 |
sys.version = '3.6.7 (default, Oct 21 2018, 04:56:05) \n[GCC 5.4.0 20160609]' sys.prefix = '/usr' |
Verify the output is the same as running python in a shell and doing a
|
1 2 |
import sys print(sys.prefix) |
If everything matches, you should be good to go. Now you can replace the content of your wsgi file with something like the following:
|
1 2 3 4 |
import sys import os from attnGANserver import app as application |
If something doesn’t work, a good place to see what went wrong is the Apache error log located in apache2/logs directory in the error_log file. All of the WSGI/Python related errors will be written to this file.
This setup works, but is a bit cumbersome to set up and tough to debug. The outputs of my print statements in the Python file are sent to the Apache log files instead of being printed to the console which makes debugging more difficult. I was also having some memory issues where the memory consumption after each HTTP request was increasing and causing the system to freeze. There is probably some way to get around all these issues, I just didn’t spend too much time investigating them. I will now describe the second method which I found much easier to set up.
Using gunicorn+Flask
In the previous approach, mod_wsgi is running our Python application as Apache daemon processes. In this approach, your application endpoint is directly visible to the internet. Another way is to run our application as a local server (not visible to the internet) and setting up a “reverse proxy”. As Apache receives a request from a client, the request itself is proxied to one of these backend local servers, which then handles the request, generates the content and then sends this content back to httpd, which then generates the actual HTTP response back to the client. See this for a very nice description of how this works and this for a simple example of how to set this up. The picture before describes the difference between the two approaches.
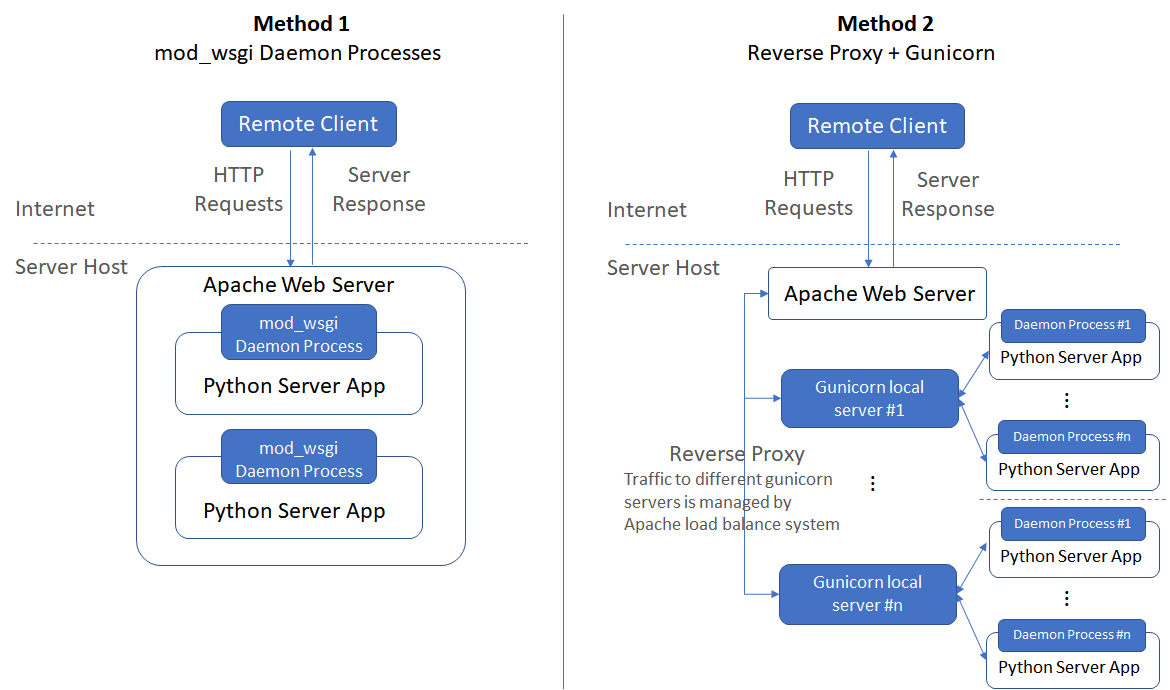
A reverse proxy can be set up as follows:
|
1 2 3 4 |
<Location "/attn_gan_impl"> ProxyPass "http://127.0.0.1:5000" ProxyPassReverse "http://127.0.0.1:5000" </Location> |
This proxies requests directed to “attn_gan_impl” URI to the local server running on port 5000. The above snippet can be placed in one of your Apache config files. I placed it at the end of the bitnami-apps-prefix.conf file.
Now when you run your Flask application on port 5000, you should be able to communicate with it over the internet via <your-base-url>/attn_gan_impl.
The reverse proxy mechanism also allows you to set up load balancing, where you run multiple servers and tell Apache about these servers using the BalancerMember directive. If one of your servers crashes or is heavily loaded, Apache will proxy incoming traffic to another server using a load balancing algorithm that balances based on I/O bytes.
Note that the when you “run Flask” you are actually running Werkzeug’s development WSGI server, and passing your Flask app as the WSGI callable. The Flask development server is not intended for use in production. It is not designed to be particularly efficient, stable, or secure. This brings us to gunicorn.
Setting up gunicorn
gunicorn is a Python WSGI HTTP Server for UNIX. While using Flask with gunicorn, you don’t have to launch the Flask servers directly. Instead, you tell gunicorn about your Python+Flask application using a wsgi config and gunicorn will launch and manage your Python application. Launching gunicorn is very simple:
|
1 2 |
$/home/bitnami/.local/bin/gunicorn -c ../conf/gunicorn.conf -b 127.0.0.1:5000 wsgi --workers=1 --name attnGAN |
The first argument is the location of the gunicorn configuration file. In my setup, the gunicorn.conf file simply contains the location of the logs
|
1 2 |
accesslog = "my-app-location/logs/gunicorn_access.log" errorlog = "my-app-location/logs/gunicorn_error.log" |
You can also provide these arguments in the command line using –error-logfile and –access-logfile.
The second argument is the URL and port where I want my servers to listen. This should match the value you specify in the ProxyPass directive in your Apache config. The third argument (wsgi) is the name of the python file that contains the wsgi application code. My wsgi.py looks like this:
|
1 2 3 4 |
import sys import os from attnGANserver import app as application |
This is identical to the wsgi file we used with the mod_wsgi based method, except that the extension is a .py whereas the extension of the previous file was a .wsgi extension. I’m not sure if this matters. The third argument is the number of processes that gunicorn should launch and the last argument assigns a name to those processes so it is easier to find them in the output of ps or htop.
Let’s now look at the number of processes argument in more detail. gunicorn documentation recommends setting this to 2-4 x $(NUM_CORES). The idea is that with multiple processes running, concurrent requests can be distributed across available processes, making your application more responsive. However this only works for stateless servers, where handling a request doesn’t depend on some prior action (such as an init function). In my implementation, the user first selects the desired model (bird/coco) and then selects the caption and hits generate. Selecting the model causes the init function in Python to be called, where the word encoding and the attention GAN models are loaded. Hitting generate calls the generate function in Python where the loaded models are used. If the number of workers is more than 1, it is possible that gunicorn will call init in one process and generate in another one. This will create a problem as the process that runs generate will not have the model loaded in its memory. You can see which process runs a function using the os.getpid() function.
|
1 |
print("Init request handled by process id: {}".format(os.getpid())) |
The problem can be easily solved by calling init with all available models in your wsgi.py file. That way all the models will be loaded at application startup and available when generate is called.
|
1 2 3 4 5 6 7 |
import sys import os from attnGANserver import app as application from attnGANserver import init init('bird') init('coco') |
Now you can specify more than one workers without any issues. This will use more RAM though as each worker process will load both models. You can see the total memory consumption using the Linux htop utility. In my setup, I’m using 2 worker processes.
That’s it! Hope this was useful.
Leave a Reply